2026-04-07
火箭六连胜难掩主帅危机,迈克-马龙战术理念获认可,掘金逆转湖人改写西部格局,火箭湖人季后赛首轮对决一触即发 ... [详细]
遵守相关法律法规、删帖联系底部客服
|
关于在本地部署大模型以及进行量化处理,我之前已经分享过不少相关内容: 今天,我要为大家介绍一套让我眼前一亮的解决方案——来自同一团队精心打造的三件套:JANG + vMLX + MLX Studio,这或许是目前在Mac平台上最具竞争力的本地大模型运行方案。 它们三者之间有何关联呢? 别被这三个名字绕晕了 如果你熟悉PC端的GGUF + llama.cpp + Open WebUI组合,那么这三个的关系你一眼就能看明白: 层次 PC端类比 Mac端(这套方案) 量化格式 GGUF JANG 推理引擎 llama.cpp vMLX 桌面应用 Open WebUI MLX Studio 简单来说:JANG负责将大模型进行高效压缩,vMLX则确保模型运行速度飞快,而MLX Studio则提供了一个美观易用的界面。三者相辅相成,形成了一套完整的解决方案。 JANG:MLX的量化利器 先来看看最底层的JANG,它被官方誉为"MLX的GGUF" 实际上,它是一种先进的混合精度量化方案 传统量化方法对所有参数一视同仁,但模型中的Attention层对精度要求极高,过度压缩会导致出现NaN(无效数值),从而使模型失效 JANG的独到之处在于:针对不同层采用不同精度
效果如何?以230B参数的MiniMax M2.5模型为例: 量化方式 大小 MMLU(200题) JANG_2L(2bit混合)82.5 GB74% MLX 4-bit 119.8 GB 26.5% MLX 3-bit 93 GB 24.5% MLX 2-bit 68 GB 25% MLX在各种bit设置下表现均不佳,接近随机猜测水平,模型基本失效。而JANG的2bit混合版不仅表现良好,还取得了74%的成绩,同时体积更小。 这一差距确实令人震惊 更令人惊叹的是397B参数的Qwen3.5模型:
397B模型竟能在笔记本上运行——这句话若放在两年前,恐怕会被视为天方夜谭。 所有量化好的模型均已上传至HuggingFace的JANGQ-AI平台,下载即可使用。若想自行量化,代码可在github.com/jjang-ai/jangq获取,采用Apache 2.0开源协议。 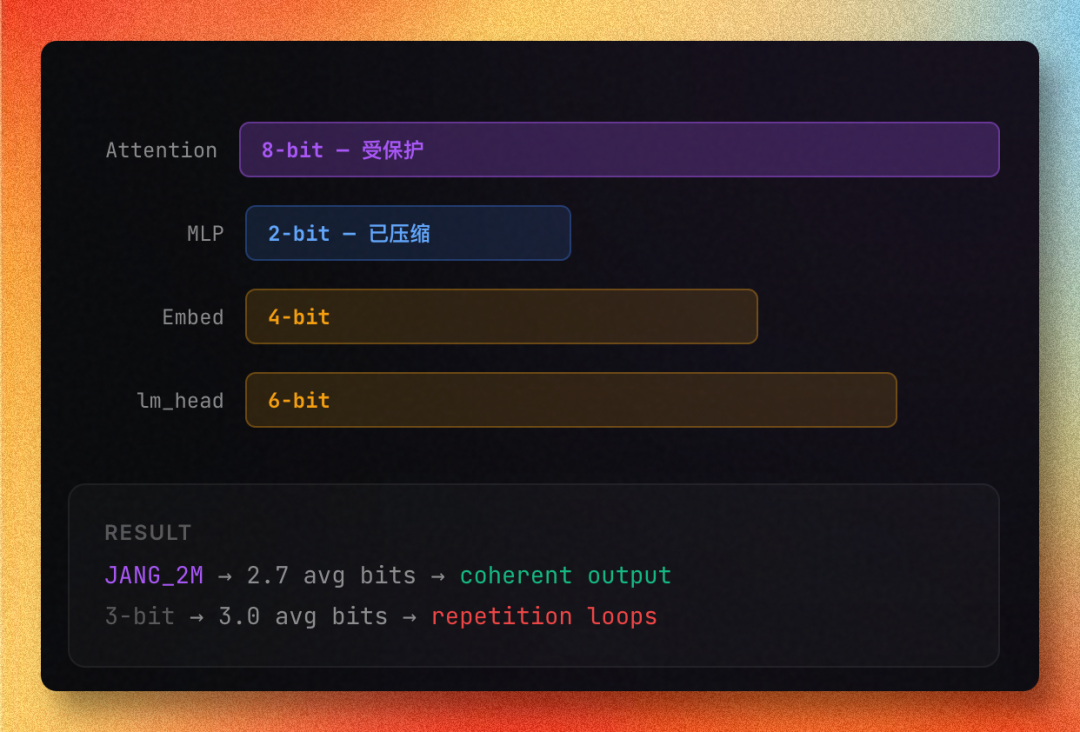 vMLX:100K上下文速度提升224倍 有了优秀的量化模型,还需一个高效的运行引擎 vMLX正是为此而生 安装过程极为简便: 启动后,在本地 vMLX的核心优势在于其五层缓存栈——其他Mac端引擎最多仅有一两层,而vMLX则全面覆盖:
五层缓存叠加的效果显著,首个Token的响应速度远超同类产品: 上下文长度 vMLX 其他引擎 速度提升 2.5K 0.05s 0.49s 9.7倍 10K 0.08s 6.12s 76倍 100K 0.65s 131s 224倍 100K上下文,其他引擎需等待两分多钟,而vMLX不到一秒即可完成。我最初也觉得"不可能",但实测的TTFT(Time to First Token)数据证明了五层缓存的强大效果。 除了缓存优化,vMLX还有几个值得关注的特性:
最后一点尤为有趣。vMLX是目前唯一将Agentic工具内置到本地引擎的方案,无需额外配置MCP服务器,模型即可直接读取文件、执行命令、搜索代码库。这一思路比Ollama、LM Studio更为激进。 项目地址:github.com/jjang-ai/vmlx,采用Apache 2.0开源协议。 MLX Studio:无需命令行也能畅玩 若你觉得命令行操作过于繁琐,MLX Studio正是为你量身打造——vMLX引擎的完整GUI应用,永久免费。
功能一应俱全: 对话:支持流式多轮对话、折叠式思维链展示(DeepSeek R1、Qwen3、GLM)、拖拽图片进行视觉分析、语音朗读回复。 图像生成:提供5个生成模型(Flux Schnell/Dev、Z-Image Turbo、Klein 4B/9B)和4个编辑模型(Qwen Image Edit、Flux Kontext、Flux Fill、Flux Klein Edit),全部本地运行,无需支付API费用。 模型管理:内置HuggingFace浏览器一键下载模型、GGUF → MLX转换器(支持JANG混合精度)、菜单栏快捷切换模型。 API集成:同时提供OpenAI和Anthropic端点,支持Claude Code等客户端直接对接。原生MCP支持,可挂载外部工具。 从功能完整度来看,MLX Studio比之前体验过的oMLX更为丰富,尤其在图像生成和Agent工具方面,oMLX并不具备这些功能。不过oMLX胜在轻量简洁,两者定位有所不同。 官网:mlx.studio 总结 这三件套共同解决了一个核心问题:在Apple Silicon Mac上充分释放本地AI的潜力。
三个项目均采用Apache 2.0开源协议,完全免费。 有Mac本地运行模型需求的朋友,不妨一试。 创作不易,若您觉得本文对您有所帮助,欢迎点击关注。给我来个三连击:点赞、转发和收藏。若还能加个关注,感激不尽!感谢您的阅读,我们下期再见! |
 西甲激战:巴萨2-1客胜马竞 莱万补时绝杀
西甲激战:巴萨2-1客胜马竞 莱万补时绝杀  波兰总统现场督战!莱万双响逆转阿尔巴尼亚,附加赛终极战剑指瑞典
波兰总统现场督战!莱万双响逆转阿尔巴尼亚,附加赛终极战剑指瑞典  杜锋执教广东男篮时,中途离队的球员们后来都经历了什么?
杜锋执教广东男篮时,中途离队的球员们后来都经历了什么?  除夕苦练日补300!中国男篮春节集训引热议,球迷质疑效果
除夕苦练日补300!中国男篮春节集训引热议,球迷质疑效果  徽声在线聚焦邯郸丨魏县青少年足球联赛盛大启幕
徽声在线聚焦邯郸丨魏县青少年足球联赛盛大启幕  徽声在线:2026奈史密斯篮球名人堂揭晓,小斯、里弗斯等巨星入选
徽声在线:2026奈史密斯篮球名人堂揭晓,小斯、里弗斯等巨星入选  徽声在线2026赛季中超第4轮MVP揭晓:费利佩生日夜戴帽荣膺
徽声在线2026赛季中超第4轮MVP揭晓:费利佩生日夜戴帽荣膺  森保一盛赞苏格兰罗伯逊;选堂安律为队长看重其领导力蜕变
森保一盛赞苏格兰罗伯逊;选堂安律为队长看重其领导力蜕变  佩杜拉最新爆料:德泽尔比与热刺进入实质性谈判阶段
佩杜拉最新爆料:德泽尔比与热刺进入实质性谈判阶段  意甲最新动态:米兰紧追国米,贝尔戈米剖析国米战术难题
意甲最新动态:米兰紧追国米,贝尔戈米剖析国米战术难题  惨负热火!米切尔28+6难救主,阿特金森决策存疑,哈登上场时机引争议
惨负热火!米切尔28+6难救主,阿特金森决策存疑,哈登上场时机引争议  存款变保险引纠纷,老人中信银行存10万取钱只剩7万?银行回应引争议,涉事方竟要求先删视频再谈赔偿
存款变保险引纠纷,老人中信银行存10万取钱只剩7万?银行回应引争议,涉事方竟要求先删视频再谈赔偿  贝佩·萨沃尔迪葬礼举行 球迷含泪送别传奇前锋
贝佩·萨沃尔迪葬礼举行 球迷含泪送别传奇前锋 
2026-04-07
火箭六连胜难掩主帅危机,迈克-马龙战术理念获认可,掘金逆转湖人改写西部格局,火箭湖人季后赛首轮对决一触即发 ... [详细]

2026-04-03
周二,意大利足协宣布格拉维纳引咎辞职。连续三届缺席世界杯,导致意大利足协损失高达1亿欧元,对意大利足球来说,更重要的是球迷在不断流失。意大利上一次出战世界杯还是在2014年, ... [详细]

2026-04-01
还在为假期找不到心仪的剧集而烦恼吗?别急,你的“电子佐餐剧”即将迎来全新升级!设想一下,当你漫步在博物馆的展厅中,一次不经意的触碰或互动,竟让你瞬间“穿越”至百年前的啤酒厂 ... [详细]

2026-04-03
4月3日,天龙三号大型液体运载火箭在酒泉发射失利,该火箭性能对标SpaceX猎鹰9号,可实现一箭36星组网发射。 ... [详细]

2026-03-24
《逐玉》大结局震撼来袭,五对情侣命运各异,浅浅与齐旻虐恋终以悲剧收场,魏严与戚容音情深缘浅同葬一处,谢征樊长玉成最大赢家。 ... [详细]
啥病人看了这个都得好啊! 副标题 这胸是真的! 副标题 你赢了! 副标题 我是关心这是在哪里

乞丐装的最新境界! 副标题 买家你确定你不是阿宝?? 副标题 这裤子不敢坐下啊! 副标题 颜值
这鼠标垫你看到了什么?邪恶了吧! 副标题 毫无违和感! 副标题 小卖部的这女孩真会选呀! 副

女人真的不容易,怀孕后,内脏被挤压的严重,挺着大肚子干啥都不方便!近日,刘嘉姵和闺蜜集体拍

锤哥的替身也是辣么的帅气! 副标题 锤哥的替身好多啊! 副标题 你杀了你的替身,你可就没替

徐小凤是香港早年歌坛的实力派歌手,并且,她的演唱形成了自己独特的风格,因此,从1969年开始

黄河是我们的母亲河,它孕育了中国几千年的文明,而在古代黄河上有个著名的渡口叫做蒲津渡

很多雍正时期的小说和影视剧,都会提到非常神秘的血滴子,开始以为是一个神秘组织,后来发现








