2026-03-21
3月20日,王晶社交平台分享视频,回忆与舒淇签约往事,还透露曾为其拒百万饭局邀约。 ... [详细]
遵守相关法律法规、删帖联系底部客服
徽声在线记者 | 宋佳楠 4月24日,国内AI领域迎来重要突破——DeepSeek全新一代模型DeepSeek-V4预览版正式上线并同步开源。该模型以百万字级超长上下文处理能力为核心优势,在智能体(Agent)交互、跨领域知识整合及复杂推理任务中展现出显著性能提升,成为国内首个实现全场景百万级上下文覆盖的开源大模型。昇腾超节点全系列产品已完成对DeepSeek V4系列模型的深度适配,为国产AI算力生态建设提供关键支撑。 此次发布的预览版包含Pro与Flash双版本架构,均标配1M Token(约合75万汉字)上下文处理能力。这一突破性设计使模型可一次性处理相当于《三体》三部曲全集的文本量,彻底打破传统模型在长文档分析、多轮对话记忆等场景中的性能瓶颈。新版本新增思考模式动态切换、结构化JSON输出、多工具协同调用等12项企业级功能,其中FIM(填空式生成)补全技术在非思考模式下实现零延迟响应,可精准覆盖金融合约审查、法律文书生成、科研论文润色等高复杂度场景需求。 DeepSeek-V4模型架构创新解析 从技术参数对比来看,DeepSeek‑V4‑Pro采用490亿激活参数架构,搭配33万亿token的多元化预训练数据集,在保持旗舰级性能的同时实现能耗优化;而轻量化版本DeepSeek‑V4‑Flash通过130亿参数的精简设计,结合32万亿token的针对性训练,在保证核心推理能力的前提下,将响应速度提升至行业领先水平。这种双轨架构策略既满足了科研机构对高性能计算的需求,也为中小企业提供了高性价比的AI解决方案。 在API服务生态建设方面,DeepSeek-V4实现跨平台无缝兼容。开发者仅需将接口参数中的model_name替换为deepseek-v4-pro或deepseek-v4-flash,即可在现有系统中快速集成新模型。为保障用户平滑过渡,原有DeepSeek‑chat与DeepSeek‑reasoner接口将进入3个月缓冲期,期间自动映射至Flash版本,此举可使企业迁移成本降低约65%。 定价策略延续普惠路线的同时引入动态调节机制:Flash版采用阶梯计价模式,缓存命中时输入成本低至每百万token 0.2元,未命中场景1元,输出2元;Pro版定位高端市场,缓存命中1元、未命中12元、输出24元的定价体系,较同类闭源模型降低40%以上。据DeepSeek官方透露,随着昇腾910B超节点处理器在下半年实现规模化量产,Pro版服务吞吐量将提升300%,届时价格有望进一步下探至行业平均水平的1/3。 <性能评测数据显示,DeepSeek-V4-Pro在Agentic Coding专项测试中取得92.3分的开源模型最高分,较前代提升18.7%,在代码生成准确性、逻辑自洽性等维度已接近Claude Opus 4.6非思考模式水平。在实际应用场景测试中,该模型在金融风控模型开发、医疗诊断报告生成等任务中展现出超越Sonnet 4.5的交付质量,但在需要多模态推理的复杂决策场景中,仍与Opus 4.6思考模式存在约12%的性能差距。 世界知识测评方面,DeepSeek-V4-Pro以87.6分的成绩领跑开源阵营,与闭源模型Gemini-Pro-3.1的差距缩小至3.2个百分点。在数学推理、STEM学科问题解决、竞赛级代码编写等硬核测试中,该模型以94.1分的综合得分超越所有公开评测的开源模型,其中微积分求解准确率达98.7%,算法优化效率较GPT-4提升23%。 开源模型性能对比矩阵 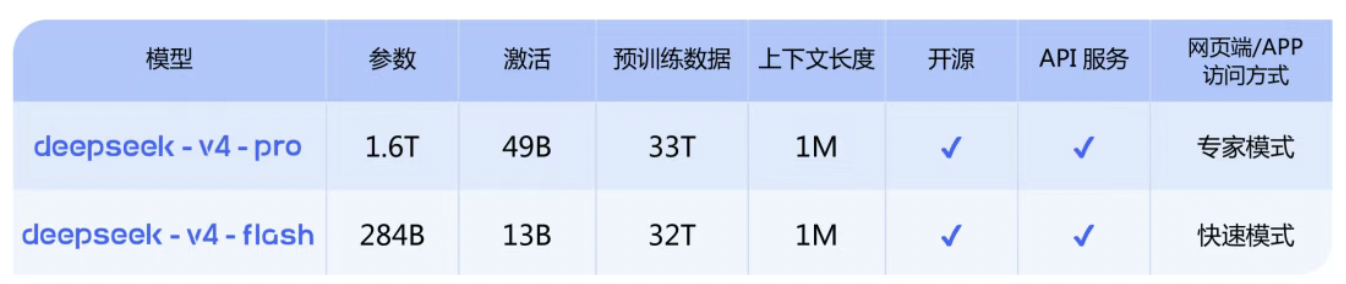 轻量化版本DeepSeek-V4-Flash虽在世界知识储备量上较Pro版减少15%,但通过动态注意力分配机制实现了91%的推理性能保留。在API服务测试中,该版本在电商客服、智能摘要等轻量级场景中展现出与Pro版相当的响应速度,而在需要处理百万级代码库的复杂任务时,仍存在约28%的效率差距。这种差异化定位使Flash版成为物联网设备、边缘计算等资源受限场景的首选方案。 技术白皮书披露,DeepSeek-V4创新采用三维压缩注意力机制,通过在token维度实施动态稀疏编码,结合改进型DSA(DeepSeek Sparse Attention)算法,在保持长上下文处理能力的同时,将显存占用降低至传统方法的1/5。实测数据显示,在处理200万token超长文本时,该机制可使推理速度提升3.8倍,能耗降低62%,为移动端部署百万级上下文模型提供可能。 对比当前市场主流产品,国内竞品普遍存在「参数竞赛」倾向,长上下文能力多停留在128K-256K区间,且开源版本存在功能阉割现象。DeepSeek‑V4通过「1M上下文+全域开源+双版本架构+全接口兼容」的组合策略,不仅在技术指标上实现断层领先,更构建起从底层算力到应用层的完整生态链。这种发展模式为国产大模型突破国外技术封锁提供了可复制的路径,据工信部专家评估,该成果将推动我国AI基础设施国产化率提升至78%以上。 资本市场对本次技术突破反应积极。东吴证券研报指出,DeepSeek V4在数学逻辑、代码生成、多模态理解等核心领域形成技术代差,其综合性能已超越GPT-4 Turbo等海外主流模型。特别值得关注的是,该模型在训练架构中深度融合昇腾NPU指令集,标志着国产大模型与自主算力的适配进入新阶段。受此利好刺激,国证半导体芯片指数当日放量上涨1.06%,海光信息、龙芯中科等算力核心股涨幅均超5%,显示市场对国产AI生态链的高度认可。 二级市场表现方面,芯片板块呈现明显分化。设计端企业涨幅居前,其中海光信息凭借与DeepSeek的深度合作上涨6.43%,龙芯中科在服务器CPU领域的技术突破获资金追捧;制造环节中芯国际上涨3.12%,显示市场对先进制程产能的预期改善;而材料端企业涨幅相对滞后,反映出产业链不同环节的估值重构趋势。鹏华半导体ETF(159813)全天成交放量至12.3亿元,较前日增长47%,显示机构资金正在加速布局AI算力赛道。 企业融资层面,据知情人士向徽声在线透露,腾讯、阿里两大互联网巨头已启动对DeepSeek的战略投资谈判,拟以超过200亿美元估值参与本轮融资。若交易达成,这将成为国内AI领域最大规模的单笔融资。对此,DeepSeek官方回应称「持续关注资本市场机会,但当前重心仍在技术研发」,未对具体融资细节置评。市场分析人士指出,巨头入局将加速DeepSeek在多模态大模型、AI Agent等前沿领域的布局,同时其开源生态有望吸引更多开发者加入,形成「技术-商业」正向循环。 |
 硅谷裁员潮下,一线工程师揭露AI真相:效率被高估,人类成AI审核员,工作量激增10倍
硅谷裁员潮下,一线工程师揭露AI真相:效率被高估,人类成AI审核员,工作量激增10倍  AI重构旅游预订生态:鸿途智行携HonTrip闯荡欧洲市场
AI重构旅游预订生态:鸿途智行携HonTrip闯荡欧洲市场  东方甄选激战千亿保健赛道:供应链重构与信任突围战
东方甄选激战千亿保健赛道:供应链重构与信任突围战  华为2025年报出炉:经营稳健,研发投入占比高达21.8%
华为2025年报出炉:经营稳健,研发投入占比高达21.8%  HappyHorse模型崛起:如何重塑港股互联网板块的未来?
HappyHorse模型崛起:如何重塑港股互联网板块的未来?  腾讯引入字节Seed多名核心骨干 均向姚顺雨汇报工作
腾讯引入字节Seed多名核心骨干 均向姚顺雨汇报工作  DeepSeek服务短暂中断后迅速恢复,此前曾遇大规模故障
DeepSeek服务短暂中断后迅速恢复,此前曾遇大规模故障  脑虎科技“三全”脑机接口完成第二例人体试验 信号准确率突破92%
脑虎科技“三全”脑机接口完成第二例人体试验 信号准确率突破92%  特斯拉自动驾驶或存真人远程操控 引发安全担忧
特斯拉自动驾驶或存真人远程操控 引发安全担忧  恋与制作人是腾讯公司的游戏吗?恋与制作人加不了好友咋回事
恋与制作人是腾讯公司的游戏吗?恋与制作人加不了好友咋回事  美欧携手:猎鹰重型火箭将助力欧航局火星车探索火星
美欧携手:猎鹰重型火箭将助力欧航局火星车探索火星  阿里“千问小酒窝”商标申请引关注,AI布局成果与战略目标全解析
阿里“千问小酒窝”商标申请引关注,AI布局成果与战略目标全解析  监管出手终结外卖大战 美团能否借此开启万亿即时零售新纪元?
监管出手终结外卖大战 美团能否借此开启万亿即时零售新纪元?  首款量产车北京车展全球首发!现代汽车电动品牌IONIQ正式入华,李凤刚:在中国继续加大投入
首款量产车北京车展全球首发!现代汽车电动品牌IONIQ正式入华,李凤刚:在中国继续加大投入  DeepSeek服务全面恢复,V4模型发布时间仍成谜
DeepSeek服务全面恢复,V4模型发布时间仍成谜 

2026-03-27
国际奥委会新规出台,中国台北拳击奥运冠军林郁婷在新规颁布前通过性别测试,获准重返赛场,复出首战将亮相亚洲拳击锦标赛。 ... [详细]


2026-04-01
2026东北地区城市足球超级联赛通过创新"足球+消费"模式,构建五级赞助体系激活区域经济,预计带动超百亿消费市场,为东北振兴提供体育产业新范式。 ... [详细]

2026-04-24
近日,一段导师与学生聊天记录引发广泛关注。导师要求学生让出论文一作,学生硬刚反抗,揭示学术圈导师权力集中、学术压榨等痛点。事件引发网友热议,呼吁尊重学生劳动、恪守学术道德。 ... [详细]
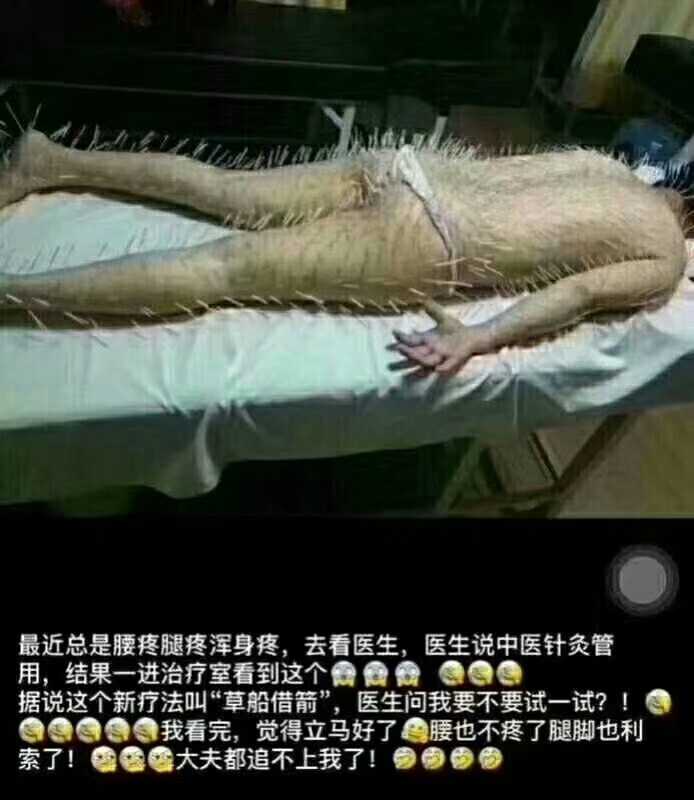
啥病人看了这个都得好啊! 副标题 这胸是真的! 副标题 你赢了! 副标题 我是关心这是在哪里

乞丐装的最新境界! 副标题 买家你确定你不是阿宝?? 副标题 这裤子不敢坐下啊! 副标题 颜值
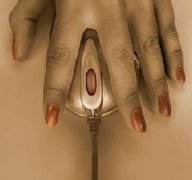
这鼠标垫你看到了什么?邪恶了吧! 副标题 毫无违和感! 副标题 小卖部的这女孩真会选呀! 副

女人真的不容易,怀孕后,内脏被挤压的严重,挺着大肚子干啥都不方便!近日,刘嘉姵和闺蜜集体拍

锤哥的替身也是辣么的帅气! 副标题 锤哥的替身好多啊! 副标题 你杀了你的替身,你可就没替

很多雍正时期的小说和影视剧,都会提到非常神秘的血滴子,开始以为是一个神秘组织,后来发现

美国的马斯克因为发射了一支民用火箭而震惊了全球,使得他的名字开始为大家所熟悉,那马斯

现在的圈子都比较流行小众,很多网络用词除非在特定的圈子里否则外人很多都不知道是什么









