2026-03-30
罗马诺透露曼联求购托纳利优先级极高,球员持开放态度;曼城则领跑安德森争夺战,阿森纳也在关注托纳利转会动态。 ... [详细]
遵守相关法律法规、删帖联系底部客服
|
“不诱于誉,不恐于诽,率道而行,端然正己。”这句古训,恰如其分地描绘了DeepSeek在人工智能领域的坚定步伐。 近期,DeepSeek新模型的发布、与华为芯片的适配以及融资传闻,成为了科技圈的热门话题。4月24日,在万众瞩目之下,DeepSeek-V4新模型终于揭开神秘面纱。 此次发布的V4模型,以其1M超长上下文、强大的Agent能力、丰富的世界知识和卓越的推理性能,成为了市场的焦点。而DeepSeek在发布会上那16字的表态,更是被视为对市场舆论的一次有力回应,彰显了其坚持价值观、率道而行的决心。 尽管此前DeepSeek内部研发人员有所流动,但从此次发布的节奏和技术作者名单来看,创始人梁文锋对于AGI的追求依旧坚定不移。DeepSeek明确表示:“我们将始终秉持长期主义的原则理念,在探索与实践中稳步前行,不断向实现AGI的目标迈进。” 有分析人士曾认为,DeepSeek-R1在2025年的惊艳表现后,背负着AI大模型“扫地僧”的盛名,V4大模型或许难以再续辉煌。然而,DeepSeek却以“率道而行”的姿态,打破了这一预言。 此次DeepSeek-V4新模型的一大亮点,是其与华为等国产芯片的适配。英伟达CEO黄仁勋在4月中旬的一档播客节目中直言:“DeepSeek的进步意义非凡。倘若有一天,像DeepSeek这样的成果率先在华为平台上绽放,那对美国而言,无疑将是一个沉重的打击。” 随着靴子的落地,国产大模型与国产半导体的结合,为AI领域开启了全新的叙事篇章。 浙江浙大网新图灵信息科技有限公司总工程师兼数科事业部总经理杨庆在接受徽声在线记者采访时表示,DeepSeek-V4的发布,不仅仅是一次模型参数的飞跃,更是一场涉及模型架构、应用范式与底层算力生态的系统性变革。 DeepSeek-V4结构创新,引发海外开发者热议 根据DeepSeek最新技术报告,此次发布的DeepSeek-V4系列预览版本,包含了两款强大的专家混合(MoE)语言模型。 它们分别是参数量高达1.6T(激活参数490亿)的DeepSeek-V4-Pro,以及参数量为2840亿(激活参数130亿)的DeepSeek-V4-Flash。 此前DeepSeek官网悄然上线的专家模式,正是此次发布的新模型DeepSeek-V4-Pro的对应版本,而快速模式则对应DeepSeek-V4-Flash。
此次更新的DeepSeek-V4系列新模型,以其百万字超长上下文、领先的Agent能力、世界知识和推理性能,在国内与开源领域均独占鳌头。 DeepSeek披露的技术报告显示,DeepSeek-V4系列在架构和优化方面实现了多项关键突破。  首先是混合注意力架构,它结合了压缩稀疏注意力(CSA)与重度压缩注意力(HCA),显著提升了长上下文的处理效率; 其次是流形约束超连接(mHC),它增强了传统残差连接的性能;此外,还有Muon优化器,它实现了更快的收敛速度和更高的训练稳定性。DeepSeek使用超过32T的多样化、高质量标记对两个模型进行了预训练,随后通过完整的后训练流程进一步解锁并提升了其性能。 超高上下文效率是此次新模型的一大亮点。DeepSeek方面透露,在百万词元的上下文设置下,DeepSeek-V4-Pro所需的单词元推理FLOPs计算量仅为DeepSeek-V3.2的27%,所需KV缓存空间也仅为其10%。基于这一突破,DeepSeek也宣布,从4月24日开始,1M(一百万)上下文将成为DeepSeek所有官方服务的标配。
新模型发布后,在国内外开发者社区引发了巨大反响。 专注于评估大语言模型(LLM)的排行榜Vals AI在社交媒体上表示:“DeepSeek-V4现在是我们Vibe Code Benchmark上排名第一的开源权重模型,而且优势明显。甚至击败了像Gemini3.1Pro这样的前沿闭源模型。”
密歇根州立大学理论物理学及计算数学、科学与工程学教授Steve Hsu则从使用体验角度给出了高度评价。他贴出一段让模型推演复杂问题的完整推理轨迹,称赞其“在数学和物理方面又快又聪明,最终结果精致且准确”。 英伟达人工智能研究员Rick Lamers在看到内部基准测试排名后,也评价道:“DeepSeek-V4在智能体工程方面的可用性看起来非常高,感觉非常棒”。 DeepSeek新模型适配华为芯片,黄仁勋也表达担忧 《徽声在线》记者注意到,DeepSeek技术报告提及了性能与开源Mega-Kernel:“我们在 NVIDIA GPU和 HUAWEI Ascend NPU平台上验证了该细粒度EP方案。与强大的非融合基线方法相比,该方案在通用推理工作负载中实现了1.50至1.73倍的加速比,在延迟敏感场景(如强化学习部署和高速智能体服务)中加速比最高可达1.96倍。” 此前DeepSeek-V4迟迟未发布,市场有消息称DeepSeek新模型在和华为芯片做适配。从最新DeepSeek技术报告来看,DeepSeek新模型除了适配原有的英伟达芯片外,也在积极与华为昇腾芯片进行适配。 目前,DeepSeek API已同步上线V4-Pro与V4-Flash。然而,从DeepSeek公布的API接入价格来看,当前V4-Pro接入的成本仍然较高。对此,DeepSeek表示,受限于高端算力,目前Pro的服务吞吐十分有限,预计下半年昇腾950超节点批量上市后,Pro价格将大幅下调。
谜底终于揭开,DeepSeek同时适配了英伟达和华为芯片。对于DeepSeek和华为芯片的适配,英伟达CEO黄仁勋此前不乏担忧。 在4月中旬的一期播客访谈中,黄仁勋表示,要是哪天像DeepSeek这样的成果先在华为平台上出现,那对美国会是非常糟糕的结果。他认为,如果DeepSeek针对华为的架构进行优化,那么对英伟达来说,将处于不利地位。 黄仁勋的担心,究竟从何而来? 杨庆在接受徽声在线记者采访时表示,DeepSeek V4的发布,其意义远不止于单一模型参数的跃升,而是一场涉及模型架构、应用范式与底层算力生态的系统性变革。 杨庆分析,从技术层面看,V4新模型带来的百万级上下文窗口以及深度强化的推理规划机制,将从根本上拓展AI处理复杂长程任务的边界。这意味着Agent从“能对话”走向“能办事”的“最后一公里”正在被打通。 从产业生态层面看,V4与国产算力底座的深度适配尤为关键。杨庆表示,若这一适配在生产环境中获得验证,其示范效应将加速“去CUDA化”(即摆脱对英伟达CUDA生态的依赖)进程,推动国产AI芯片从“可用”走向“好用”,并带动上下游的协同成熟。对于全球AI竞争格局而言,这标志着中国大模型产业正迈入以“任务执行效率”和“算力自主生态”为核心竞争力的新赛段。 DeepSeek人才流动引关注,梁文锋定力依旧稳健 一个鲜为人知的细节是,DeepSeek-V4的技术报告披露了作者名单。在“研究与工程”的作者名单里,有近300人,其中有10人已经离开了DeepSeek团队。 此前,DeepSeek的人才流动情况备受市场关注。 一度有消息称,DeepSeek正在进行首次外部融资,目的是为了留住那些以股票期权作为薪酬的员工,防止他们被竞争对手挖走。但截至发稿,徽声在线记者尚未确认该消息的真实性。 然而,不可否认的是,一鸣惊人的DeepSeek的确存在部分人才流动的情况。但从此次披露的技术报告名单来看,DeepSeek的研究人才依旧阵容强大。 《徽声在线》记者梳理发现,在近一年的人才流动中,影响最大的当属郭达雅的离职。郭达雅于2026年3月正式离开DeepSeek,其后加入字节跳动。 比郭达雅更早离开的是王炳宣,2025年底,王炳宣被腾讯姚顺雨团队挖走。王炳宣是DeepSeek第一代大语言模型DeepSeek LLM的核心作者,此后参与了历代模型的训练工作。 另一位核心成员魏浩然约在2026年春节前后离开。魏浩然是DeepSeek-OCR系列的核心作者,该系列在文档识别与多模态处理方面有着重要布局。截至目前,魏浩然的具体去向尚未公开披露。 在时间线上,近一年内最早离开的核心成员是阮翀。阮翀的离职时间约在2025年上半年,离职后他进入了一段休整期,直到2026年1月才正式官宣加入自动驾驶创业公司元戎启行。 此外,被外界称为“AI天才少女”的罗福莉也在这一轮人才流动中离开了DeepSeek。2025年11月12日,罗福莉正式官宣加入小米,出任小米MiMo大模型负责人。 但另一方面,DeepSeek也在加大人才招聘力度。从释放的岗位来看,DeepSeek正在强化Agent研究人才储备。4月24日发布的一系列招聘岗位中,有不少和Agent相关的岗位。譬如Agent全栈开发工程师、Agent深度学习算法研究员、Agent数据策略工程师等。 杨庆认为,未来三至五年,AI行业的核心演进方向将围绕三个关键词展开:智能体化、软硬协同与可信执行。AI应用形态将从“模型即服务”加速演进为“智能体即生产力”。企业不再满足于获得文本答案,而是期望部署能够自主规划、调用系统、完成闭环任务的数字化劳动力。 其次,软硬协同将成为降本增效的主战场。推理成本已成为商业化的核心约束变量,未来竞争将从算法延伸至芯片指令集、推理框架与模型压缩的全栈效率之争。最后,可信执行将成为规模化部署的前提。当Agent开始操作生产系统、处理隐私数据时,可审计性、安全边界与幻觉治理将从学术议题上升为合规刚需。 然而,国产AI仍在不断进化之中,DeepSeek在中国AI发展路径中,也仍保有对技术的极致探索精神。谈及DeepSeek创始人梁文锋,网易副总裁、网易智企总经理阮良此前在接受徽声在线记者采访时认为,作为浙大校友,梁文锋身上有着一种极客专注精神,不会因为外界干扰而影响自身的判断和方向。 4月24日,DeepSeek在最后也强调“我们将始终秉持长期主义的原则理念,在尝试与思考中踏实前行,努力向实现AGI的目标不断靠近。” |
 特斯拉自动驾驶或存真人远程操控 引发安全担忧
特斯拉自动驾驶或存真人远程操控 引发安全担忧  美“猎户座”飞船完成绕月任务 顺利溅落圣迭戈海域
美“猎户座”飞船完成绕月任务 顺利溅落圣迭戈海域  AI智能体重构电商生态:淘工厂天猫超市领跑,阿里能否抢占B端AI基建制高点?
AI智能体重构电商生态:淘工厂天猫超市领跑,阿里能否抢占B端AI基建制高点?  债市动态精选 | 美团评级展望遭下调;多家发债主体2025年业绩呈现分化
债市动态精选 | 美团评级展望遭下调;多家发债主体2025年业绩呈现分化  苹果天价全球抢购手机内存,市场格局或生变
苹果天价全球抢购手机内存,市场格局或生变  半导体深处稀缺战略金属铟价格飙升,创十年新高引关注
半导体深处稀缺战略金属铟价格飙升,创十年新高引关注  小鹏汽车碰撞后散架?法务部正式回应澄清谣言
小鹏汽车碰撞后散架?法务部正式回应澄清谣言  智谱重磅发布GLM-5V-Turbo:多模态Coding基座模型引领未来编程新潮流
智谱重磅发布GLM-5V-Turbo:多模态Coding基座模型引领未来编程新潮流  阿里云宣布:部分MU模型单元服务价格将适度调整
阿里云宣布:部分MU模型单元服务价格将适度调整  喜讯!我国高精度温室气体探测卫星发射成功,碳监测能力大飞跃
喜讯!我国高精度温室气体探测卫星发射成功,碳监测能力大飞跃  雷军、蔡崇信中国发展高层论坛发声,共话未来产业创新与发展
雷军、蔡崇信中国发展高层论坛发声,共话未来产业创新与发展  小米徐洁云严正驳斥“雷军车内维权”谣言:恶意传播者将受法律严惩
小米徐洁云严正驳斥“雷军车内维权”谣言:恶意传播者将受法律严惩  “AI艺人库”风波:未解行业难题,反添焦虑情绪
“AI艺人库”风波:未解行业难题,反添焦虑情绪  科技日报|黄仁勋首谈生死观;Arm发布革命性AI芯片;特斯拉机器人加速量产
科技日报|黄仁勋首谈生死观;Arm发布革命性AI芯片;特斯拉机器人加速量产  突破百亿产值后,具身智能产业如何跨越GPT3.0门槛?头部企业共议发展路径
突破百亿产值后,具身智能产业如何跨越GPT3.0门槛?头部企业共议发展路径 
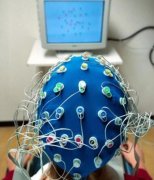
2019-06-23
我们在很多科幻电影和小说的桥段中可以看到这样的一个场景:主人翁用自己大脑的意念控制了某个物体的行为,可以随心所欲的让物体移动、变形等等。当然这是科幻中的场景,但是不可否认的是意念真的是存在的,所谓的意念就是你的想法,你大脑想要做的一件事就是 ... [详细]

2026-04-22
北京时间4月18日亚冠精英联赛1/4决赛,吉达联合0-1不敌町田泽维亚,主帅孔塞桑赛后怒喷主裁判马宁执法不公,引发争议。 ... [详细]

2026-03-31
伊朗伊斯兰革命卫队宣布,美军因边境雷达及后勤系统频遭攻击而撤离,多架预警机和加油机被击落,仓库被毁,未来将扩大打击范围。 ... [详细]

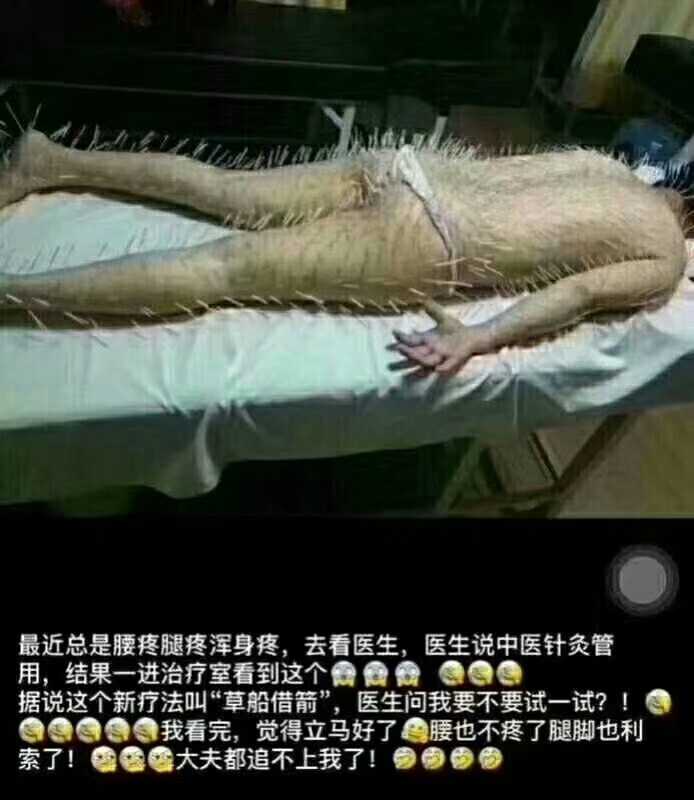
啥病人看了这个都得好啊! 副标题 这胸是真的! 副标题 你赢了! 副标题 我是关心这是在哪里

乞丐装的最新境界! 副标题 买家你确定你不是阿宝?? 副标题 这裤子不敢坐下啊! 副标题 颜值
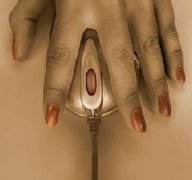
这鼠标垫你看到了什么?邪恶了吧! 副标题 毫无违和感! 副标题 小卖部的这女孩真会选呀! 副

女人真的不容易,怀孕后,内脏被挤压的严重,挺着大肚子干啥都不方便!近日,刘嘉姵和闺蜜集体拍

锤哥的替身也是辣么的帅气! 副标题 锤哥的替身好多啊! 副标题 你杀了你的替身,你可就没替

英国王室最令人津津乐道的当属查尔斯王子和戴安娜王妃以及卡米拉之间的三角恋情,作为英

徐小凤是香港早年歌坛的实力派歌手,并且,她的演唱形成了自己独特的风格,因此,从1969年开始

很多有关佛教的影视剧上都会出现一个名词,舍利子。我们都知道舍利子是五彩色的晶体,集齐









